Anatomy of Internet Search Engine
For some unfortunate souls, SEO is just the learning of tricks and techniques that, according to their understanding, should propel their site into the top rankings on the major search engines.
This knowledge of how SEO works can be helpful for a time; however, it contains one fundamental flaw: changing rules. Search engines are constantly evolving to keep up with the SEO best practice in much the same way that Norton, McAfee, AVG, or any other anti-virus software companies are always trying to keep up with the virus writers.
Basing your entire website’s future on a straightforward set of rules (read: tricks) about how the search engines will rank your site contains an additional flaw; more factors are being considered than any SEO is aware of and can confirm. That’s right; I will freely admit that there are factors at work that I may not be aware of, and even those that I know if I cannot with 100% accuracy give you the exact weight they are provided in the overall algorithm. Even if I could, the algorithm would change a few weeks later and what’s more, hold your hats for this one; there is more than one search engine.
So, what can we do if we cannot base our Search Engine Optimization on a set of hard-and-fast rules? The key, my friends is not to understand the tricks but rather what they accomplish. Reflecting on my high school math teacher Mr. Barry Nicholl I recall a silly story that had a significant impact. One weekend he had the entire class watch Dumbo The Flying Elephant (there was going to be a question about it on our test).
Why? The lesson we were to get from it is that formulas (like tricks) are the feather in the story. They are unnecessary, and yet we hold on to them in the false belief that it is the feather that works and not the logic. Indeed, the tricks and techniques are not what works but rather the philosophy they follow, which is their shortcoming.
Internet Search Engine: So What Is Necessary?
To rank a website highly and keep it ranking over time, one must optimize it with one original understanding that a search engine is a living thing. Obviously, this is not to say that search engines have brains. I will leave those tales to Orson Scott Card and other science fiction writers; however, their very nature results in a lifelike being with far more storage capacity.
If we consider how a search engine functions, it goes out into the world, follows the road signs and paths to get where it’s going, and collects all of the information in its wake. From this point, the data is sent back to a group of servers where algorithms are applied in order to determine the importance of specific documents. How are these algorithms generated?
They are created by human beings with lots of experience in understanding the fundamentals of the Internet and the documents it contains and who can also learn from their mistakes and update the algorithms accordingly. Essentially we have an entity that collects data, stores it, and then sorts through it to determine what’s important, which it’s happy to share with others, and what’s unimportant, which it keeps tucked away.
Internet Search Engine: So Let’s Break It Down?

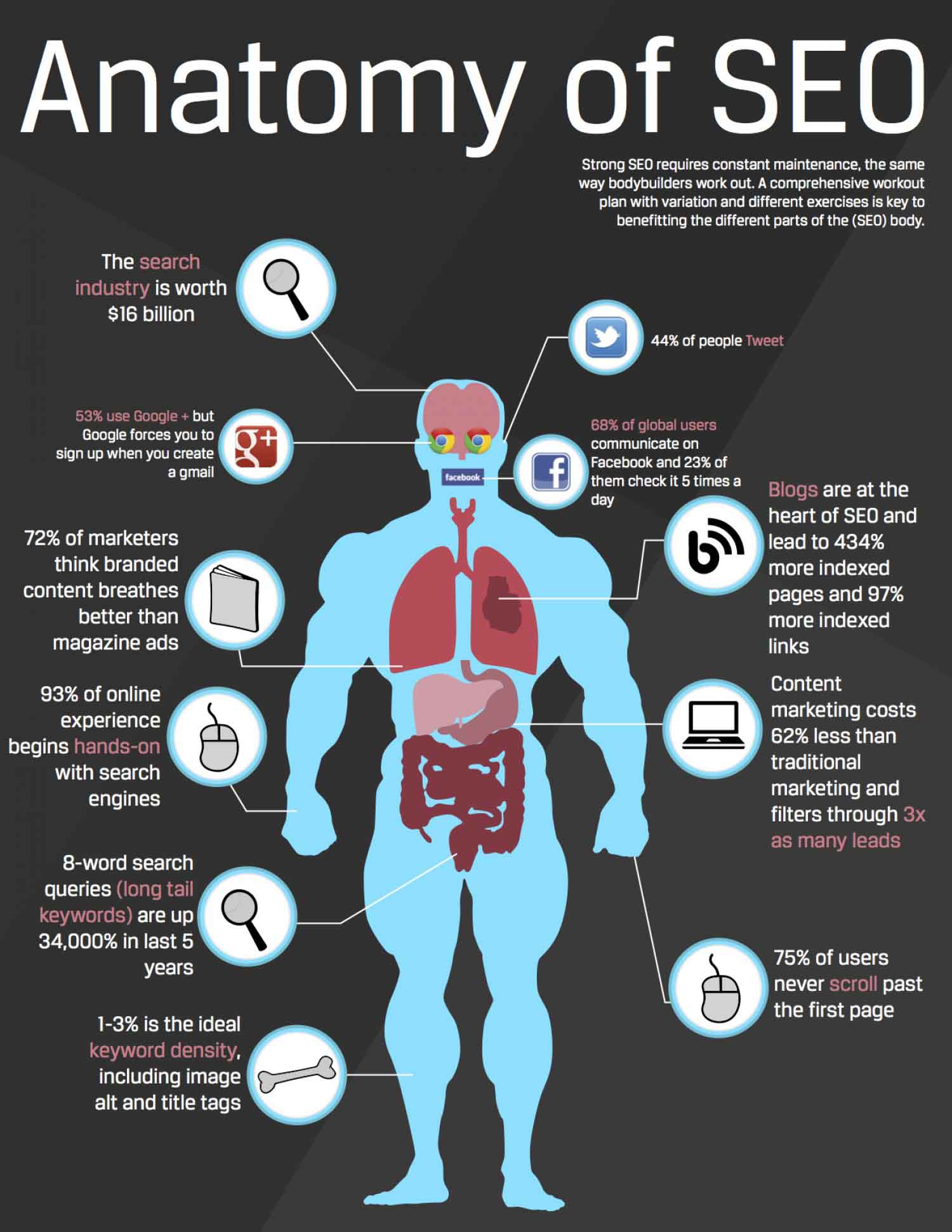
To gain a fundamental understanding of what a search engine is, it’s simple enough to compare it to the human anatomy as, though not breathing, it contains many of the same core functions required for life. And these are:
The Lungs & Other Vital Organs
The lungs of a search engine and the vast majority of vital organs are contained within the datacenters in which they are housed. Be it in the form of power, Internet connectivity, etc. As with the human body, we do not generally consider these vital in defining who we are; however, we’re certainly grateful to have them and need them all to function correctly.
The Arms & Legs
Please think of the links from the engine itself as the arms and legs. These are the vehicles by which we get where we need to go and retrieve what needs to be accessed. While we don’t commonly think of these as functions when considering SEO, these are the purpose of the entire thing. Much as the human body is designed primarily to keep you mobile and access other things, so is the whole search engine intended mainly to access the outside world.
The Eyes
The eyes of the search engine are the spiders (AKA robots or crawlers). These are the 1s and 0s that the search engines send out over the Internet to retrieve documents. In the case of all the major search engines, the spiders crawl from one page to another following the links, as you would look down various paths along your way.
Fortunately for the spiders, they travel mainly over fiber optic connections. So their ability to move at light speed enables them to visit all the paths they come across, whereas we, as humans, have to be a bit more selective.
The Brain
The brain of a search engine, like the human brain, is the most complex of its functions and components. The brain must have instinct, knowledge, and learn to work correctly. A search engine (and by the search engine, we mean the natural listings of the major engines) must also include these critical three components to survive.
The Instinct
The instinct of search engines is defined in its core functions, that is, the crawling of sites and either the inability to read specific types of data or the programmed response to ignore files meeting specific criteria.
Even the programmed responses become automated by the engines and thus fall under the category of instinct, much the same as the westernized human instinct to jump from a large spider is learned. An infant would probably watch the spider or even eat it, meaning this is not an automatic human reaction.
The instinct of search engines is important to understand however, once one understands what can and cannot be read and how the spiders will crawl a site this will become instinct for you too and can then safely be stored in the `autopilot? Part of your brain.
The Knowing
Search engines know by crawling. What they know goes far beyond what is commonly perceived by most users, webmasters, and SEOs. While the vast storehouse we call the Internet provides billions upon billions of pages of data for the search engines to know they also pick up more than that. Search engines know some different methods for storing data, presenting data, prioritizing data, and of course, a way of tricking the engines themselves.
While the search engine spiders are crawling the web, they are grabbing the stores of data that exist and sending it back to the datacenters, where that information is processed through existing algorithms and spam filters where it will attain a ranking based on the engine’s current understanding of the way the Internet and the documents contained within it work.
Similar to the way we process an article from a newspaper based on our current understanding of the world, the search engines process and rank documents based on what they understand to be true in the way documents are organized on the Internet.
The Learning
Once it is understood that search engines rank documents based on a specific understanding of the way the Internet functions, it then follows that in order to ensure that new document types and technologies are able to be read and that the algorithm is changed as new understandings of the functionality of the Internet are uncovered a search engine must have the ability to learn”.
Aside from a search engine needing the ability to properly spider documents stored in newer technologies, search engines must also have the ability to detect and accurately penalize spam and as well as accurately rank websites based on new understandings of the way documents are organized and links arranged. Examples of areas where search engines must learn on an ongoing basis include but are most certainly not limited to:
- Understanding the relevance of the content between sites where a link is found;
- Attaining the ability to view the content of documents contained within new technologies such as database types, Flash, etc.;
- Understanding the various methods used to hide text, links, etc. to penalize sites engaging in these tactics;
- Learning from current results and any shortcoming in them, what tweaks to current algorithms, or what additional considerations must be taken into account to improve the relevancy of the results in the future.
The learning of a search engine generally comes from the uber-geeks hired by and the users of the search engines. Once a factor is taken into account and programmed into the algorithm it they move into the knowing category until the next round of updates.
How This Helps in SEO
This is the point at which you may be asking yourself. This is all well and good but exactly how does this help ME?? An understanding of how search engines function, how they learn, and how they live is one of the most important agreements you can have in optimizing a website.
This understanding will ensure that you don’t simply apply random tricks in hopes that you’ve listened to the right person on the forums that day but rather that you consider what is the search engine trying to do and does this tactic fit with the long-term goals of the engine.
For a while keyword density spamming was all the rage among the less ethical SEO as was building networks of websites to link together to boost link popularity. Neither of these tactics works today and why? They do not fit with the long-term goals of the search engine. Search engines, like humans, want to survive. If the results they provide are poor then the engine will die a slow but steady death, and so they evolve.
When considering any tactic you must take into account, does this fit with the long-term goals of the engine? Does this tactic, in general, serve to provide better results for the largest number of searches? If the answer is yes, then the tactic is sound.
For example, the overall relevancy of your website (i.e. does the majority of your content focus on a single subject) has become more important over the past year or so. Does this help the searcher? The searcher will find more content on the subject they have searched on larger sites with more massive amounts of related content and thus this shift does help the searcher overall. A tactic that includes the addition of more content to your site is thus a solid one as it helps build the overall relevancy of your website and gives the visitor more and updated information at their disposal once they get there.
Another example would be link building. Reciprocal links are becoming less relevant and reciprocal links between unrelated sites are virtually irrelevant. If you are engaging in reciprocal link building ensure that the sites you link to are related to your site’s content. As a search engine, I would want to know that a site in my results also provided links to other relevant sites, thus increasing the chance that the searcher would find the information they are looking for one way or another without having to switch to a different search engine.
In Short: Internet Search Engine
In short, think ahead. Understand that search engines are organic beings that will continue to evolve. Help feed them when they visit your site; they will return often and reward your efforts. Use unethical tactics, and you may hold a good position for a while but in the end, if you do not use tactics that provide good overall results, you will not hold your position for long. They will learn.
Searchenginejournal by Dave Davies